Первый нейросетевой русско-татарский переводчик с функцией голосового ввода TatSoft от Академии наук РТ запустили в 2024 году. Но в приложении нет функции загрузки аудиозаписи, а телеграм-бот делает некачественную транскрибацию. Эксперты указывают, что основная причина — в нехватке лингвистических данных, слабом финансировании и отсутствии мощных ресурсов. Несмотря на желание развивать такие технологии, проекты остаются на этапе разработки. «БИЗНЕС Online» протестировал речевой «расшифровщик» и убедился, что проблема до сих пор еще остается. Подробнее — в нашем материале.
 Ринат Гильмуллин в апреле 2024 года гордо презентовал первый нейросетевой машинный русско-татарский переводчик с функцией голосового ввода TatSoft, говоря, что «ни в Google, ни в «Яндексе» пока такого нет»
Ринат Гильмуллин в апреле 2024 года гордо презентовал первый нейросетевой машинный русско-татарский переводчик с функцией голосового ввода TatSoft, говоря, что «ни в Google, ни в «Яндексе» пока такого нет»
Большие надежды, маленький выхлоп
«Когда начали входить в жизнь новые технологии, такие крупные компании, как „Яндекс“, не выражали интереса к региональным языкам чисто с коммерческой точки зрения. А нам ждать тоже не очень хотелось. Поэтому решили сделать свой переводчик», — гордился директор Института прикладной семиотики Академии наук РТ Ринат Гильмуллин, презентуя в апреле 2024 года первый нейросетевой машинный русско-татарский переводчик с функцией голосового ввода TatSoft, говоря, что «ни в Google, ни в „Яндексе“ пока такого нет».
До конца 2024-го планировали включить в приложение башкирский, удмуртский, чувашский и марийский языки, в перспективе хотели создать автоматизированные кол-центры и телефонные роботы на татарском языке, сервис по автоматическому распознаванию и переводу речи выступлений, искусственный интеллект, современный литературный портал, тренажер произношений, образовательные сервисы, использующие голосовой ввод на татарском языке. Прошло почти два года, однако не то что функционал сервиса не расширился, а даже имевшиеся баги не устранили. При этом в прошлом году TatSoft демонстрировали на стенде Татарстана в Annual Investment Meeting в Абу-Даби и Российского венчурного форума.
В реальности сервис неудобен, поскольку его возможности заметно ограничены. Он может транскрибировать всего 1 тыс. знаков за раз — примерно одну минуту разговорной речи. В то же время «Яндекс» способен переводить до 10 тыс. знаков за раз, а Google — до 5 тысяч. Кроме того, качество распознавания у TatSoft оставляет желать лучшего. Он хорошо работает с четко произнесенным литературным татарским языком, но при разговорной речи, особенно у городских татар, говорящих с русскими словами или на диалекте, ошибки нередки.
Бюджету приложение обошлось в 6,8 млн рублей. Сам текстовый переводчик существует с 2019 года и, по словам Гильмуллина, за последние годы его доработали. Однако это мнение не разделяет владелец и главный редактор газеты «Безнең гәҗит» Илфат Файзрахманов. Он рассказывает, что на момент запуска TatSoft был самым востребованным русско-татарским и татарско-русским переводчиком, поскольку тогда переводчики Google и «Яндекса» плохо справлялись с татарским. «Если при переводе с татарского на русский качество было более-менее терпимым, то с русского на татарский это была просто беда. Приходилось заново самому переписывать результат машинного перевода. Когда татароязычные СМИ публиковали текст или корреспондент телерадиокомпании озвучивал материал, шутили: „Похоже, он с „Яндекс.Переводчика“ взял, ведь татары так не разговаривают“», — вспоминает собеседник.
Появление TatSoft для пользователей стало приятным сюрпризом, поскольку качество перевода существенно отличалось от Google и «Яндекса». «К сожалению, со временем татарстанский продукт не смог вытеснить эти сервисы. Даже наоборот — сейчас „Яндекс“ стал основным переводчиком у татароязычных представителей масс-медиа», — констатирует Файзрахманов.
 Председатель Всемирного форума татарской молодежи Райнур Хасанов в интервью нашей газете рассказывал, что у младотатар есть желание развивать цифровые продукты — создать расшифровщик татарского языка и разработать систему проверки грамматики татарского
Председатель Всемирного форума татарской молодежи Райнур Хасанов в интервью нашей газете рассказывал, что у младотатар есть желание развивать цифровые продукты — создать расшифровщик татарского языка и разработать систему проверки грамматики татарского
Платные и бесплатные распознаватели татарской речи. Есть ли разница?
В разговоре с «БИЗНЕС Online» коллеги из местных государственных СМИ признались, что им еще в начале прошлого года обещали предоставить качественные распознаватели татарской речи, поскольку бывает сложно переводить в текст длительные записи. Например, такие сервисы для русского языка достигают точности около 90–95%. А для татарского языка почти нет качественных преобразователей, и их заявленные возможности часто разочаровывают. Дедлайн был в декабре 2025-го, однако вопрос до сих пор остается открытым. Комментарий от Института прикладной семиотики получить не удалось.
И неясно, будет ли государство дальше участвовать в разработке татарских распознавателей речи, и то же самое касается общественных организаций. Так, председатель Всемирного форума татарской молодежи Райнур Хасанов в интервью нашей газете рассказывал, что у младотатар есть желание развивать цифровые продукты — создать расшифровщик татарского языка и разработать систему проверки грамматики татарского. Однако планы изменились и Хасанов теперь занимается «разметкой текстовых данных, а не расшифровкой звуковых». За это дело взялся другой специалист, который в настоящее время тоже приостановил разработки.
Справедливости ради стоит отметить, что у института была попытка доработать TatSoft. Они запустили телеграм-бот, обещающий перевести тексты, озвучивать и распознавать татарскую речь. Для эксперимента в бот загрузили двухминутный аудиофайл на татарском следующего содержания: «Хәлләр ничек? Шундый сорау бар иде: сезгә кунак килергә тиеш иде, килдеме ул? Килүнең нәтиҗәсе булдымы, нәрсә турында сөйләштегез? Сезнең шартларыгыз үтәлдеме?» — «Ну, алар обещать итә инде, ә аннары нәрсә булганын бер Аллаһ гына белә. Ул әле киләм ди бит». (В пер. с тат. яз.: «Как дела? Был такой вопрос. К вам должен был гость приехать, он приезжал? Так какой итог его приезда, о чем договорились? Выполнятся ли ваши условия?» — «Ну они обещать-то обещают, а потом что будет, знает только Аллах. Он сказал, что собирается к нам прийти».)
После довольно быстрой загрузки в бот данной незамысловатой беседы девайс в течение минуты выдал следующий текст: «Хәлләр алш кай шундый сорауул иде теге ди көдер саттилиядән килергә тиеш шун сөйләшәбез дигән иде бсо үзем өчен инде те нәрсә шул сөйләшмәсе белән беткәнделәр инде ул юк юксә сүзләр соң вакытты гына бу калачак мондый дип алар җәйде иң алдан белдерләр һәм соң нәрсә булган ала белә иде н керләргә туры килле әтига да кирәк иде иде әле».
Перевод, как видим, не поддается никакой логике. Но не все гладко и с платными транскрибаторами. К примеру, Speech2Text перед расшифровкой просит задать язык. Только это не улучшает работу, и снова получается что-то отдаленное от языка Тукая. Сервис также иногда распознает татарский как казахский, турецкий и азербайджанский языки, соответственно текст выдается на этих языках.
«Татарский язык не монетизируешь, на этом не заработаешь»
По словам экспертов, как звуковые переводчики, так и системы автоматического распознавания аудио работают по схожему принципу: сначала нужно ввести голосовые данные в программу, а затем — получить расшифрованный текст. Т. е. нейросеть сначала «наговаривает» целые предложения, а затем эти предложения обрабатываются и превращаются в текст. Для достижения хорошего результата требуется огромное количество таких предложений, отмечает основатель креативного агентства «Теория» и веб-дизайнер Ильдар Аюпов.
Почему же татарские звуковые системы никак не могут конкурировать с текстовыми? Причина в этом довольно простая. «Любой татарский проект ориентирован на относительно небольшую аудиторию: сотни или максимум тысячи человек, но не десятки тысяч, — объясняет Аюпов. — Поэтому проблема с материалами практически всегда возникает. В случае с текстовыми данными ситуация более решаемая — можно обработать материалы, опубликованные в татарских СМИ. Со звуком все гораздо сложнее. Их очень мало, а важна не только интонация. Модель должна научиться различать голос и шум, например, в телефонных разговорах с фоновыми помехами. Для этого нужны аудиозаписи с разным уровнем шума и в различных условиях. Использовать только „чистые“ студийные записи — значит, система будет работать лишь в идеальной среде. Аудиоматериалы должны быть максимально разнообразными. Чем больше разнообразие, тем лучше будет итоговый результат».
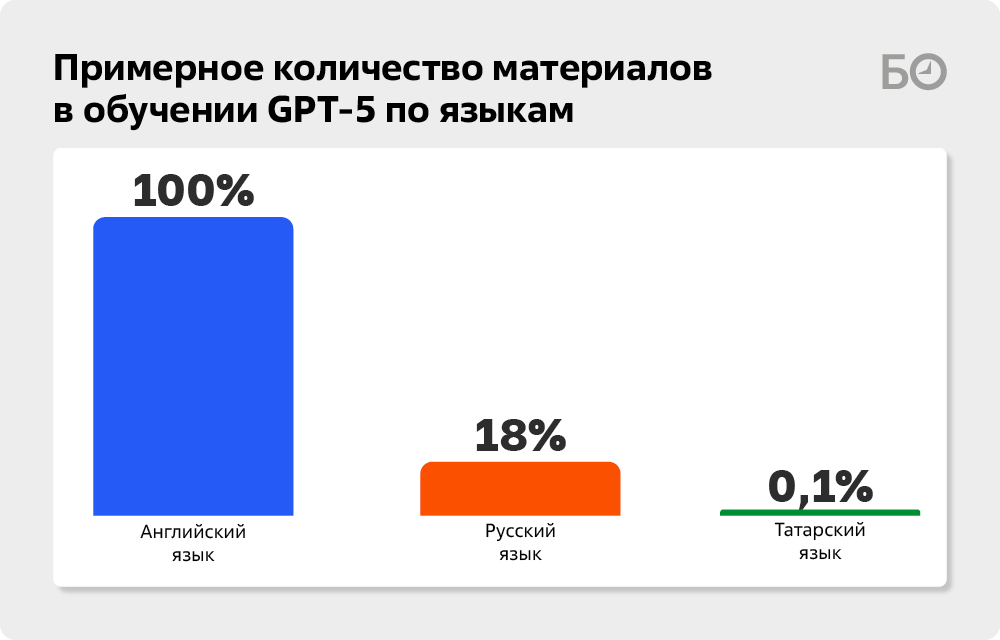
Наш собеседник рассказал, что, когда создавался ChatGPT, взяли «в „рабство“ полчища индусов и африканцев, которые сидели и создавали пару „звук – текст“, платя им смехотворные полдоллара в день». Институт семиотики же несколько месяцев собирал базу записанных речевых оборотов. Для синтеза речи из текста в голосовую речь разработчики взяли образцовый татарский язык, в этом им помогли актеры театра им. Камала. А чтобы сделать распознавание речи и превратить ее в текст, привлекли всех желающих — записи примеров предложений собирали через телеграм-бот. Собрали порядка 600 часов записи. Аюпов говорит, что если количество языкового материала, внесенного в нейросеть на английском, принять за 100%, то русский составит около 18%, а татарский — всего 0,1%.
Лингвист, разработчик устройств для марийской речи и письма Андрей Чемышев уверяет, что в ближайшее время «ГигаЧат» от Сбера сможет распознавать языки народов России, в том числе татарский, и создавать качественные системы распознавания речи, для этого, по его словам, нет никаких технических проблем.
«Нужен только отдельный мощный сервер, специальное оборудование для расшифровки. Там должны стоять хорошие графические процессоры, минимум 256 гигабайт оперативной памяти и самые быстрые NVMe-накопители. Технически все решаемо, — уверен Чемышев. — Проблема только в аппаратуре, потому что нет такого железа, куда можно было бы постоянно грузить и заниматься расшифровкой. Языковые модели есть для любого языка, и татарский здесь не исключение». К слову, спикер вместе с «Яндексом» недавно создал распознаватель марийской речи с точностью до 95%.
Еще один специалист в IT-сфере, пожелавший остаться анонимным, отмечает, что проблема с татарским сервисом заключается в недостатке данных. Когда в нейросети заливали тексты из татарских СМИ, оказалось, что большинство из них посвящено эстраде и искусству, а материалов по юриспруденции, политике, экономике или науке практически нет. Также влияет нехватка ресурсов — средств на поддержание и развитие программ, достойную оплату труда разработчиков. И третья причина — низкий интерес крупных компаний к созданию языковых моделей для татарского.
«Понятно, что татарский язык не монетизируешь, на этом не заработаешь. Этим занимаются энтузиасты в свободное время. Но, как известно, энтузиазм со временем иссякает, если его никем не поддерживают», — считает наш собеседник. Поэтому частные компании неохотно берутся за такие проекты, ведь перспективы прибыльности невелики. Это подчеркивает, что сохранение и развитие татарского языка, являющегося нематериальной культурной ценностью, — в большей мере задача государства.
Комментарии 188
Редакция оставляет за собой право отказать в публикации вашего комментария.
Правила модерирования.